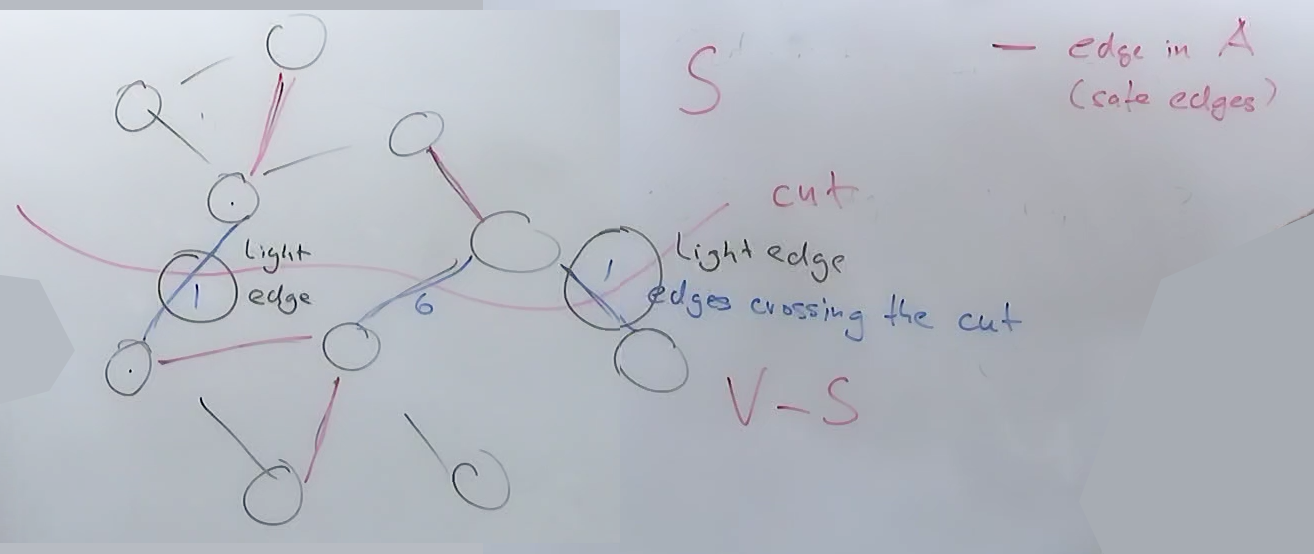
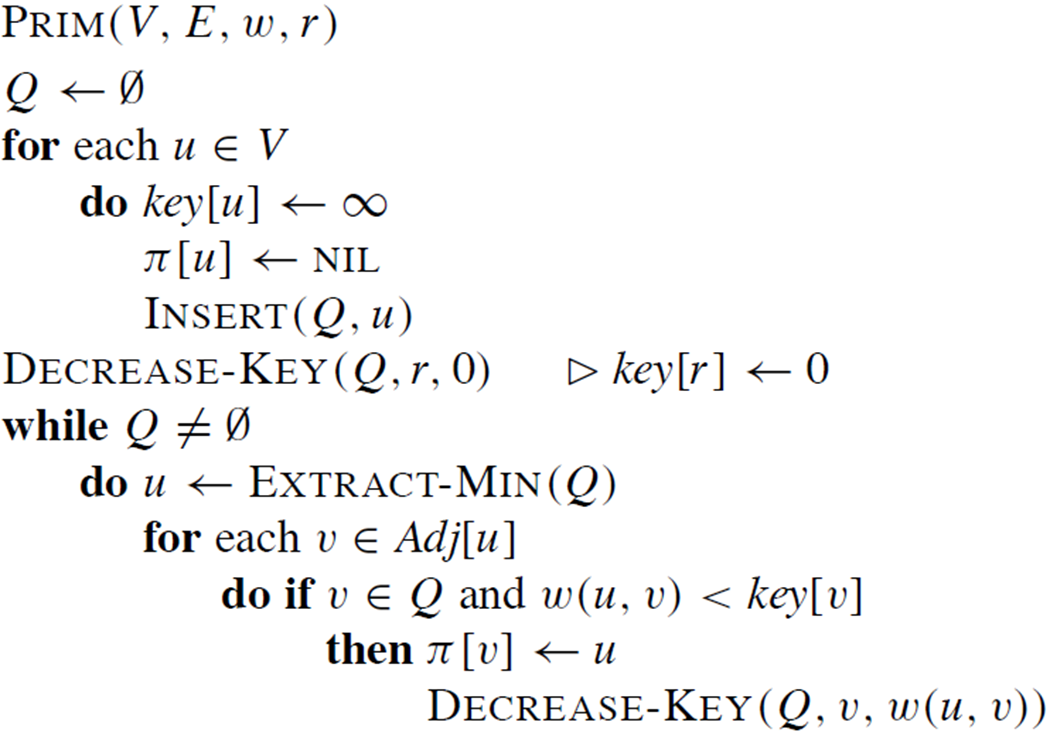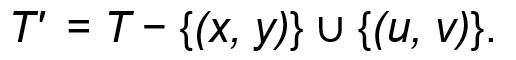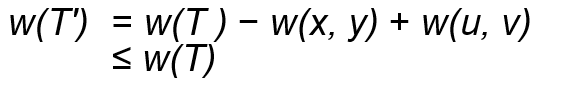문제 정의
두 점 사이의 최단 경로를 찾는 방법
입력
방향 그래프 G = (V, E)
가중치 함수 w : E → R
경로의 가중치 : 경로 p = <v0, v1, …, vk>의 가중치는 경로에 있는 모든 간선의 가중치의 합으로 정의됩니다.
즉 w(p) = w(v0, v1) + w(v1 + v2) + ... + w(vk-1, vk)이런식으로 더하면 됩니다.
기존 경로의 가중치를 구할 땐 경로의 Weight w(p)는 경로 사이에 존재하는 모든 간선의 Weight의 합입니다.
최단 경로 가중치 : 두 정점 u와 v 사이의 최단 경로 가중치는 다음과 같이 정의됩니다.

여기서 w(p)는 경로 p의 가중치입니다.
min으로 u에서 v로 가는 모든 경로 p 중에서 가중치가 가장 작은 경로를 찾습니다.
만약 u에서 v로 가는 경로가 없다면, 최단 경로 가중치는 무한대(∞)로 설정됩니다. 이는 도달할 수 없는 경로를 나타냅니다.
u에서 v까지의 최단 경로는 w(p)=δ(u,v)를 만족하는 모든 경로 p입니다.
예시

해당 예시에서는 BFS로 적용된 weight가 그래프에 보여집니다.
예시에서 최단 경로가 유일하지 않을 수 있음을 보여줍니다. 즉, 여러 경로가 동일한 최단 가중치를 가질 수 있습니다.
한 정점에서 다른 모든 정점으로 가는 최단 경로를 고려할 때, 이 경로들이 트리 구조로 조직된다는 점을 강조합니다.
이는 최단 경로 트리(Shortest Path Tree)라고 불립니다.
예를 들면 s에서 y로 가는 최단 경로가 s → y라면, y에서 다른 정점으로 가는 최단 경로도 s를 기준으로 연결됩니다.
이와 같은 방식으로 모든 정점이 s로부터의 최단 경로를 통해 연결되면, 최단 경로 트리가 형성됩니다.
최단 경로 문제들
Single-source : 주어진 출발 정점 s에서 모든 정점 v로 가는 최단 경로를 찾는 문제입니다.
Single-destination : 주어진 목적지 정점으로 가는 최단 경로를 찾는 문제입니다.
Single-pair : 두 정점 u와 v 사이의 최단 경로를 찾는 문제입니다.
이 경우, 최악의 경우에 대해 Single-source 문제를 해결하는 것보다 더 나은 방법이 알려져 있지 않습니다.
즉, 두 정점 간의 최단 경로를 찾기 위해 Single-source 문제를 해결하는 것이 최악의 경우에도 가장 좋은 방법이라는 것입니다.
All-pairs : 모든 정점 u와 v 쌍에 대해 최단 경로를 찾는 문제입니다.
음수 가중치 간선
출발점에서 도달할 수 없는 음수 가중치 사이클이 있는 경우에는 문제가 없습니다.
즉, 이 사이클에 도달할 수 없다면 최단 경로 계산에 영향을 미치지 않습니다.
하지만 만약 음수 가중치 사이클이 존재하고, 이 사이클을 계속 돌 수 있다면, 최단 경로의 가중치는 무한히 작아질 수 있습니다.
즉, w(s, v) = −∞가 되어, 사이클에 포함된 모든 정점 v에 대해 최단 경로 가중치가 무한히 작아질 수 있습니다.
경로의 가중치는 경로에 있는 모든 간선의 가중치의 합이기 때문입니다.
일부 최단 경로 알고리즘은 그래프에 음수 가중치 간선이 없을 때만 작동합니다.
음수 가중치 간선이 존재하면 알고리즘의 결과가 신뢰할 수 없게 될 수 있습니다.
정리 Lemma
최단 경로의 모든 부분 경로는 최단 경로라는 것입니다.
즉, 최단 경로의 일부를 잘라내어도 여전히 최단 경로가 유지된다는 의미입니다.
증명 Proof

잘라내기 및 붙이기 기법 (Cut-and-paste technique)을 사용하여 증명합니다.
우선 경로의 가중치 총합은 다음과 같습니다.
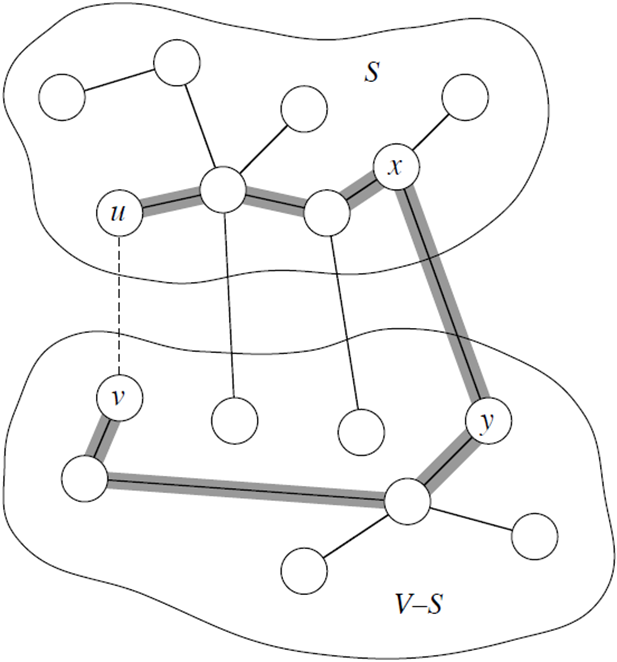
Shortest Path(u, v) = w(p) = w( p𝑢𝑥 ) + w( p𝑥𝑦 ) + w( p𝑦𝑣 )
정점 u에서 v까지의 최단 경로를 p𝑢𝑥 (u에서 x까지), p𝑥𝑦 (x에서 y까지), p𝑦𝑣 (y에서 v까지)로 나누어 설명합니다.
만약 x에서 y까지의 경로가 p𝑥𝑦 보다 짧다고 가정하면, 전체 경로 p𝑢𝑥와 p𝑦𝑣 를 포함한 경로가 더 짧아질 수 있습니다.
즉, w( p'𝑥𝑦 ) < w( p𝑥𝑦 )
그렇게 되면 최단거리였던 w(p), 즉 기존 w( p𝑥𝑦 )를 가진 경로보다 w( p'𝑥𝑦 )를 가진 w(p')가 더 작기 때문에
w(p') < w(p)이 되므로, 이는 모순이 발생하게 됩니다.
사이클 Cycle
최단 경로는 사이클을 포함할 수 없습니다. 왜냐면 위에서 얘기했던 음수 가중치 사이클을 가질 수 없기 때문입니다.
양수 가중치 사이클이 존재할 경우, 해당 사이클을 생략함으로써 더 짧은 경로를 얻을 수 있습니다.
즉, 사이클을 포함하는 경로는 최단 경로가 아닙니다.
제로 가중치 사이클이 있을 경우, 이를 사용할 이유가 없습니다.
따라서 최단 경로를 찾는 과정에서 이러한 사이클은 고려하지 않는다고 가정합니다.
Single-Source 최단 경로의 Output
Vertex V의 모든 원소 v에 대해서 얘기합니다. 즉 v ∈ V

d[v]=δ(s, v) : 정점 s에서 정점 v까지의 최단 경로 가중치입니다.
초기값으로 d[v] = ∞로 설정됩니다.
알고리즘이 진행됨에 따라 이 값은 줄어들 수 있지만, 항상 d[v] ≥ δ(s, v)를 유지해야 합니다.
즉, 항상 최단 경로보다 같거나 큰 값이어야한다는겁니다.
d[v]는 "최단 경로 추정치(shortest-path estimate)"라고 불립니다.

π[v] : 정점 v에 대한 최단 경로에서의 전임자(predecessor)입니다.
만약 전임자가 없다면, π[v]=NIL로 설정됩니다.
π 배열은 최단 경로 트리를 형성합니다. 즉, 최단 경로를 나타내는 트리 구조입니다.
초기화
모든 최단 경로 알고리즘은 이 초기화 단계로 시작합니다. 이 단계에서는 그래프의 모든 정점에 대해 초기 값을 설정합니다.
의사 코드를 보시겠습니다.

각 정점 v에 대해 :
d[v]를 무한대(∞)로 설정합니다.
이는 초기 상태에서 모든 정점까지의 최단 경로 가중치가 알려지지 않음을 의미합니다.
π[v]를 NIL로 설정합니다. 이는 해당 정점에 대한 전임자가 없음을 나타냅니다.
출발 정점 s에 대해서는 d[s]를 0으로 설정합니다. 이는 출발점에서 자기 자신까지의 거리는 0임을 의미합니다.
아래 코드에 주석을 달아봤습니다.
INIT-SINGLE-SOURCE(V, s)
// V: 그래프의 모든 정점 집합
// s: 출발 정점
for each v ∈ V // 그래프의 모든 정점 v에 대해 반복
do d[v] ← ∞ // 정점 v까지의 최단 경로 가중치를 무한대로 초기화
π[v] ← NIL // 정점 v의 전임자를 NIL로 초기화 (전임자가 없음)
d[s] ← 0 // 출발 정점 s에서 자기 자신까지의 거리는 0으로 설정
★ 간선 완화 Relax
간선 (u,v)를 완화하는 과정입니다.
이는 정점 u에서 정점 v로 가는 경로를 통해 v까지의 최단 경로 가중치를 계속 업데이트하는 과정입니다.
의사 코드를 보시겠습니다.
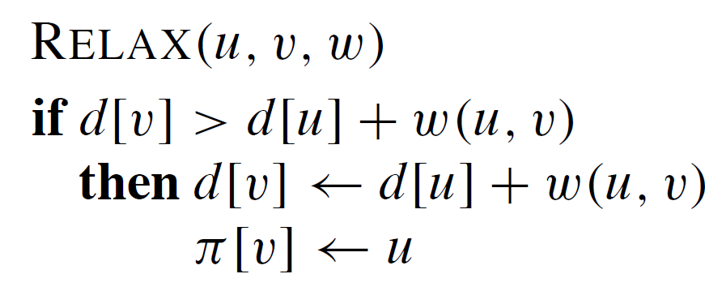
의사 코드에 주석 달아봤습니다.
RELAX(u, v, w)
// u: 시작 정점
// v: 도착 정점
// w: 간선 (u, v)의 가중치
if d[v] > d[u] + w(u, v) then
// 만약 v까지의 현재 최단 경로 가중치가
// u에서 v로 가는 경로를 통해 얻은 가중치보다 크면
d[v] ← d[u] + w(u, v) // v까지의 최단 경로 가중치를 업데이트
π[v] ← u // v의 전임자를 u로 설정하여 최단 경로를 추적할 수 있도록 함
조건: d[v]가 d[u] + w(u, v)보다 크면 d[v]를 d[u] + w(u, v)로 업데이트합니다.
이는 u를 거쳐 v로 가는 경로가 더 짧다는 것을 의미합니다.
π[v]를 u로 설정하여 v의 전임자를 u로 업데이트합니다.
예시로

그래프에서 간선 (u, v)의 가중치가 10일 때, u에서 v로 가는 경로를 완화하는 과정을 보여줍니다.
d[v] = 10, source 정점에서 u정점까지 weight가 4, u에서 v로 가는 간선의 weight가 3인 상황입니다.
d[u]+w(u, v)가 더 작으면 d[v]를 업데이트합니다.
그래서 u에서 v로 갈 때 4 + 3이니 더 작아서 10 -> 7로 업데이트합니다.
이제 d[v] = 7이 되었네요.

하나 더 보시면 u에서 v로 갈 때 4 + 3으로 7 weight를 가지지만
기존 경로 d[v] = 6이므로 더 작습니다.
그럼 업데이트할 필요가 없으니 그대로
d[v] = 6인거죠
부록
정리해보면 Single-source 최단 경로 찾기 문제는 INIT-SINGLE-SOURCE로 초기화한 뒤에 relax edges 과정을 거칩니다.
알고리즘에 따라 순서와 각 간선을 완화하는 횟수가 다릅니다.
'그냥 개발글 > 알고리즘' 카테고리의 다른 글
| 그래프 알고리즘 시간 복잡도 총정리 (0) | 2024.12.09 |
|---|---|
| 프림 알고리즘 Prim’s Algorithm (0) | 2024.12.04 |
| 크루스칼 알고리즘 Kruskal’s Algorithm (0) | 2024.12.04 |
| 최소 신장 트리 Minimum Spanning Trees (0) | 2024.12.04 |